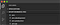
A good work is as important as a good planning. And, this is the best quote that I can think of as of now, as far as this article is concerned. Project planning and structuring is important. However, executing the project in the best manner, with implications of all the coding and architecture standards is the key. I would say, this is one of the most difficult stages of development and at the same time, the most significant too.
A poor architecture can ruin the entire project, resulting in:
· Unreadable and messy code, that will make the entire development process longer and also making the entire product, extremely difficult to test.
· Unnecessary repetition, leading to difficulty in maintaining and managing the code.
· Making implementation of new features almost impossible, due to a poor structure that is totally messy with the underlying code itself being a real problem.
Keeping the above mentioned points in mind, my team and I decided that the architecture in Spurtcommerce is highly important. I would like to list out a few points to say that the architecture we have used in Spurtcommerce is the best:
Everything has its own place in our application and we have all the common elements grouped into a folder and we have followed the following rules:
· Encapsulated everything within one directory
· Separated raw data from derived data and other data summaries. .
· Separated the data from the code.
· Used relative paths and never the absolute paths.
· Choose file names carefully that it can be easily understood, just with a glimpse that what it contains inside.
· Avoided using final in the folder name.
· Wrote ReadMe files.
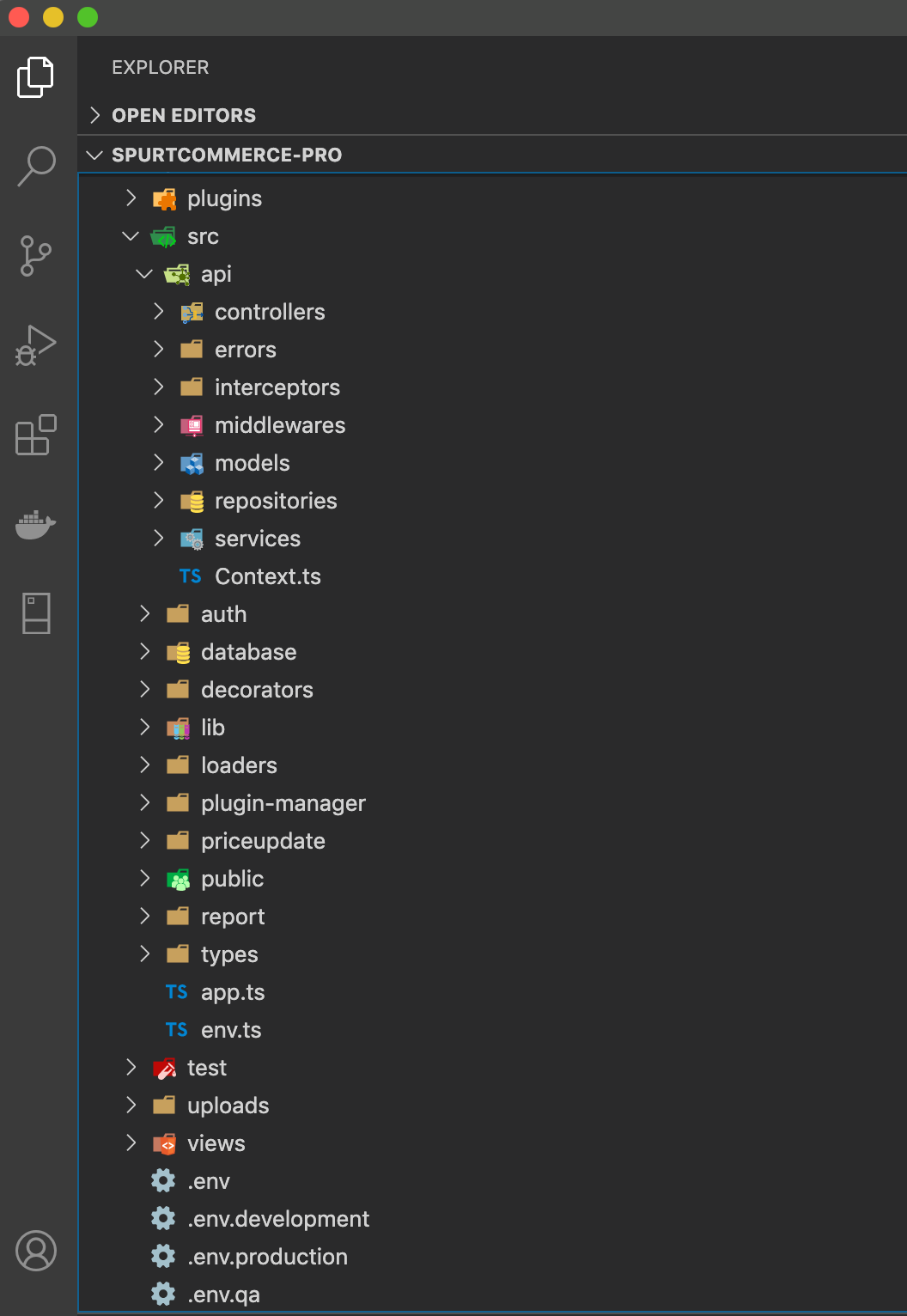
In Express framework has a pre-defined request and routes handling behavior. We have implied them to our Application, Spurtcommerce. We have split the entire architecture into monolithic blocks.
Express.js has an “app” object corresponding to HTTP. We have defined the routes by using the methods of this “app” object. This app object defines a callback function, which is called when a request is received. We have different methods in app object for different type of request — GET request, POST request and for handling all HTTP requests.
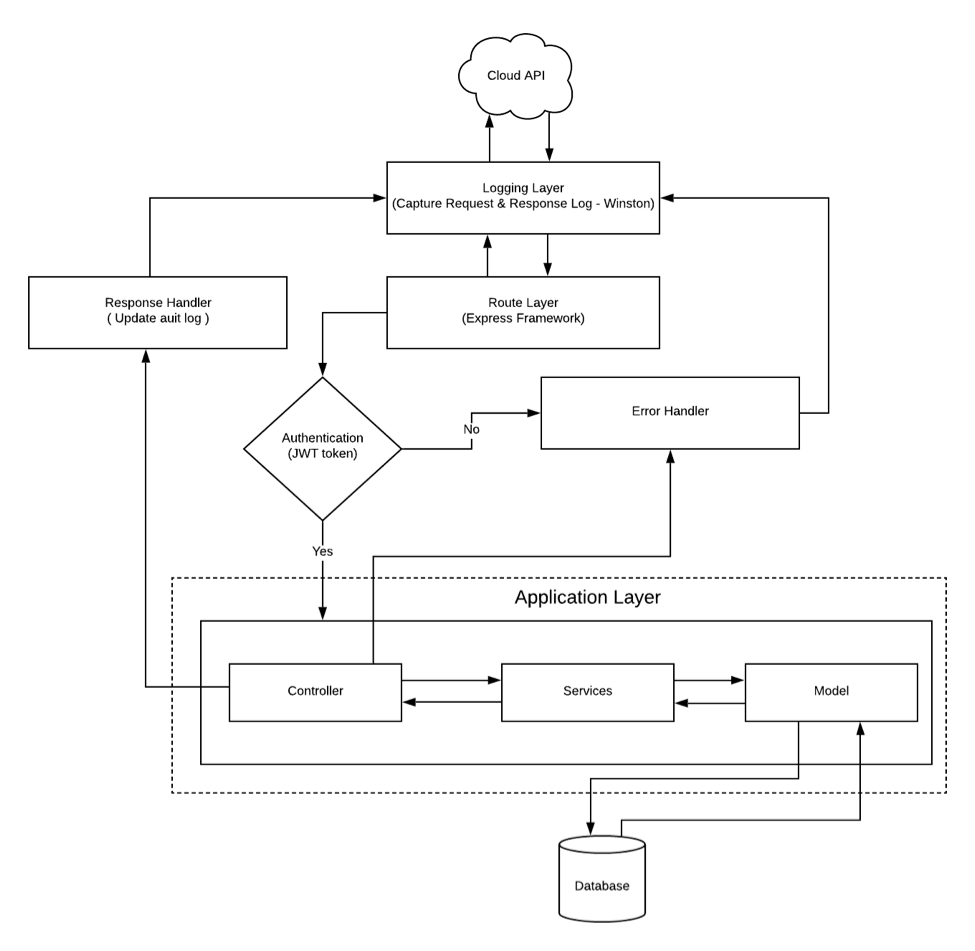
Application Layer generally should have three parts:
Controller is where all the business logics are derived from.
Services is used for fetching data from DB as well as for sending data to the Database.
Models:
· It defines the table architecture
· Each table will contain separate model files.
· Each model holds the fields within those tables.
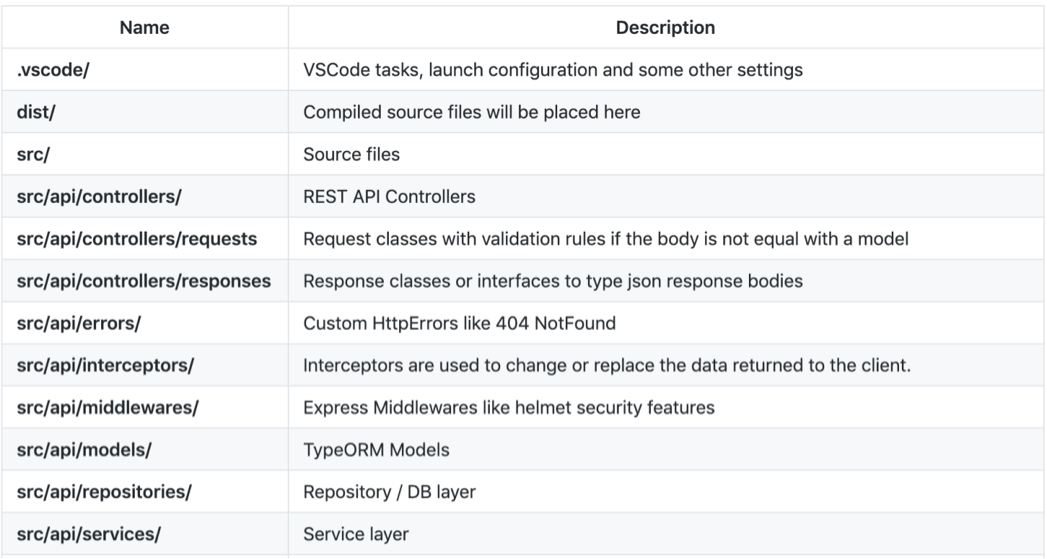
We have maintained separate configuration for each environment — DEV, QA, STG, PROD and so on. In each environment, you can find application’s global constants, Database connection entity and third party configuration details.
Why we thought doing this is an absolute necessity?
· have a single version of the actual application.
· to have an exact record of changes, along with a reference of the necessity for such a change.
· Also, for the fact that the main focus of an application is to implement business logic, and not managing configs.
· To manage various complexities of configuration data, including nested configs.
· To support for application deployed across multiple cloud providers.
· To make deployment procedures simple and structured.
We have maintained separate script files for running the application in the dev mode and for the application in the build mode and so on.
This way our production build is light weight while our development build contains all the tools and local settings that we need to work on. As a result, the Production Build will become a minified(compressed) version of the Development code, thus making the rendering of file on end user’s browser very quick and performance enhancing.

The Spurtcommerce application often calls a third party API service to retrieve certain data or to perform certain operations such as, mail sending functionality and Payment Gateway. Such functionalities have been written as separate services in our Application. When some of the business logic needs to call a third party API, then it directly injects those libraries and calls. We have used a third API layer as a proxy between the business layer and third-parties. Such an approach ensures a clear and structured service architecture that is easily understandable and manageable Through this, we have achieved the following:
· Sophisticated software architecture
· More and complete QA coverage
· Easy switching/adding 3rd-party providers
For eliminating the nuisances caused by human errors, we have made use of Linter to properly analyze source code to flag programming errors, bugs, stylistic errors, and suspicious constructs.

Throughout our Development process, we have followed the best practices, abiding by the Style Guides of ‘Google’ and ‘Airbnb’. We have followed the best practices for naming the folder, with a meaningful name (this calls us back to the Rule # 1), source file structure, formatting, for naming the variables and so on.
For every line of code and for every block of code, we have commented with why is it used and what is its objective and purpose and what logic it defines. This has made lives of all the fellow team members, especially the new comers into the team easier, as things are self-explanatory and straight forward to them. Sometimes, this has helped me when I have touched a piece of code after a long time. I’m able to recall why I did something and for what purpose.
We all know that Files that are too long are extremely hard to manage and maintain. I and my team have always made sure to keep up with a sensible file length, and if they become too long, we have tried and spitted them into modules packed in a folder with files that are related together.
In Spurtcommerce, we have used Node Promises, wherever required, throughout the application. A promise is basically advanced method of callbacks in Node. While developing an application we are pretty sure to come across a lot of nested callback functions.
If we should perform multiple nested operations, then, that can make the code messy and very complex. NodeJS terms this as “Callback Hell”. To overcome this issue, we need to eliminate the callback functions while nesting. And here is where Promises play a vital role. A Promise in Node is typically an action which will either be completed or rejected. In case of completion, the promise is kept and otherwise, the promise is broken.
Using callbacks is the simplest method for handling our asynchronous code in JavaScript. However, raw callbacks gives up on the application control flow, error handling, and semantics that were so familiar to us when using synchronous code. A solution for that is using promises in Node.js.
Promises bring in more advantages by making our code easily readable and testable while still providing functional programming semantics together with a better error-handling platform.
As experienced Developers we all know that errors are something that is part of our coding life. It is impossible that errors can be avoided fully. However, as smart Developers, we can always use the smartest approach for handling errors. In Spurtcommerce, in addition to Promises, we have used a Common Error Handler.
In the Figure — 1, you can see that we have one common Error Handler, a Common Exception Handler at the application level. Any errors across the Application gets captured in this Error Handler at the Application level. This way, we easily come to know that whatever has been captured here are errors. Also in this manner, we can easily detect those errors that otherwise are not known easily.
Developing Spurtcommerce Application was challenging, despite it was exciting for me and my team. However, the set of rules that I have mentioned above helped us put ourselves in the right path while establishing the perfect architecture for Spurtcommerce. Today, I and my team are fully satisfied that we have developed an Application that stands out in the market, in terms of the best coding standards and architecture in NodeJS.
web development company


 +91 9500107482
+91 9500107482